
Ассемблер — язык программирования низкого уровня. Ниже него только машинный код (нули и единицы).
Зачем учить ассемблер?
- понимание функционирование компьютера. Любой программист должен знать Си. Любой программист, знающий Си — должен знать ассемблер.
- умение реверсить ПО (мы живем в копирастическом мире). Для меня это в первую очередь старинные игры 90-х годов, исходников к которым не сохранилось.
- ок. коммерческая разработка. Если у вашего устройства мало памяти. — вы пишете на асме. Микроконтроллеры, загрузчики, встраиваемое ПО. Если вам надо чтобы все работало быстрее молнии под конкретную систему — вы тоже пишете напрямую под процессор, это эффективнее.
- WebAssembly (wasm) 🙂 Это не язык программирования, а технология, которая сейчас захватывает веб. На ассемблере там писать не нужно, но для оптимизации кода понимание ассемблера может пригодится.
- Ну и анализ всякой вирусной дряни. Компьютерная безопасность и антивирусные лаборатории — вот где ассемблер идет только в путь.
Ассемблер — это семейство языков. Под разных архитектуры он отличается. Не пудрите себе мозг и сосредоточьтесь на х86 для начала — по нему больше всего инфы.
Что нужно знать, чтобы войти в асм? Умение прогать на Си и понимание двоичной и шестнадцатеричной системы исчисления. Хотя можно Си и не знать, а узнать в процессе.
Итак. Как устроен ПК? Есть:
CPU. RAM. Устройства ввода-вывода.
CPU (центральное обрабатывающее устройство — central processing unit), он же процессор, внутри имеет:
Управляющее устройство. Работает с RAM. Берет из памяти адреса на инструкции, которые сохраняет потом в регистрах.
Регистры. «Встроенная» память процессора, используемая для выполнения инструкций. Фактически, это маленькие ячейки памяти, которые располагаются на процессоре; с точки зрения программиста, можно сказать, что регистр — это временная переменная без типа данных, но определенного размера.
Не стоит путайте «регистры» с «кэшем процессора»,
который по сути является филиалом RAM,
находящимся поближе к «центру принятия решений»
и где хранятся данные, часто используемые процессором,
с целью все время не дергать основную оперативку.
АЛУ (арифметико-логическое устройство). Обрабатывает данные, хранящиеся в регистрах в соответствии с инструкциями. Потом сохраняет полученную информацию в регистры или RAM.
Суть кодинга на асме — взаимодействие с регистрами процессора, который в свою очередь взаимодействую со стеком. Есть разные архитектуры: x86 (десктоп), ARM (мобилки), AVR (микроконтроллеры), но мы пока будем изучать только х86.
Тут же стоит отметить, что есть много разных ассемблеров и для x86. Самый популярный для реверсинга игрушек — MASM (Microsoft Macro Assembler), хотя есть еще, например, NASM (Netwide Assembler). Мы будем изучать кондовый MASM.
Итак, мы знаем, что регистры — специальные ячейки памяти, расположенные непосредственно в процессоре.
Процессор читает команду (aka опкод aka инструкцию) из памяти себе в регистр и начинает ее выполнение. Пример команды:
MOV EAX, 15
Здесь MOV — опкод; EAX — регистр; 15 — значение, которое кладется в регистр
1) регистры общего назначения
2) регистры специального назначения
— указатель команд
— регистр флагов
— сегментные регистры
Даже в х86 регистров дофига, но учить наизусть их все не надо, достаточно разобраться лишь в нескольких (я отметил их красным на картинке).
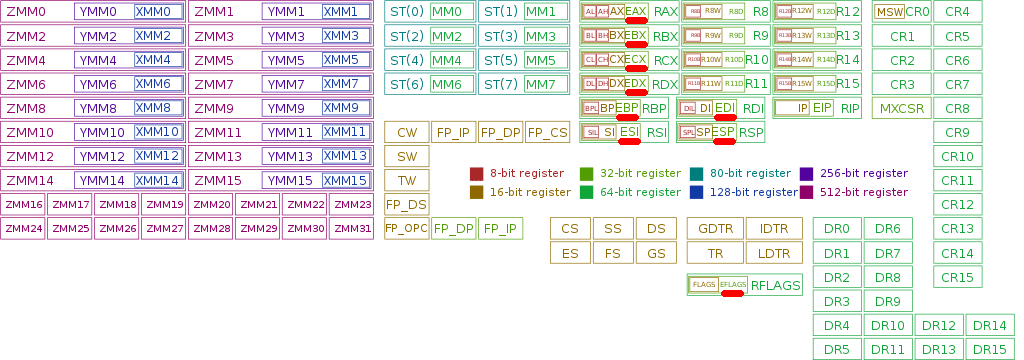
Указатель инструкции (Instruction pointer) — регистр где хранится указатель на инструкцию в стеке, которую нужно выполнить следующей; указывает её смещение (адрес) в сегменте кода. После выполнения, меняется на адрес следующей инструкции.
Далее… Регистры общего назначения aka Регистры данных. Их 8 штук; справа указано как их обычно кличут:
AX (accumulator register) — аккумулятор
BX (base register) — база (регистр базы)
CX (counter register) — счётчик
DX (data register) — регистр данных
SI (source index register) — индекс источника
DI (destination index register) — индекс приёмника (получателя)
SP (stack pointer register) — регистр указателя вершины стека (адрес самого последнего добавленного в стек элемента)
BP (base pointer register) — регистр указателя базы (адрес начала фрейма, начиная с которого в стек добавляются или извлекаются значения; его адрес всегда статичен)
Некоторые команды работают только с определёнными регистрами. Например, команды умножения и деления используют регистры EAX и EDX для хранения исходных данных и результата операции. Команды управления циклом используют регистр ECX в качестве счётчика цикла.
Регистры выше — 32битные, о чем говорит буква E начале. 64битные будет начинаться с R. Если в названии две буквы — регистр 16битный.
Регистр флагов:
EFLAGS — состояние процессора (флаг нуля, переноса и проч)
Флаги состояния (биты 0, 2, 4, 6, 7 и 11) — результат выполнения арифметических инструкций (ADD, SUB, MUL, DIV).
Флаг переноса CF (0) отмечает перенос/заём из старшего значащего бита и отмечает переполнение беззнаковых чисел. См. арифметику бинарных чисел. // Эт единственный флаг, который мы можем изменять напрямую (инструкции STC, CLC и CMC).
Флаг чётности PF ставится, когда младший значащий байт является чётным // младший — тот, что справа.
Вспомогательный флаг переноса AF ставится при переносе/заёме из бита 3-го результата.
Флаг нуля ZF становится 1, когда результат операции равен нулю.
Флаг знака SF равен значению старшего знакового бита.
Флаг переполнения OF (11) ставится, когда результат слишком длинный для размещения в регистре или ячейке памяти.
Управляющий флаг
Флаг направления DF (10) для уменьшения/увеличения адресов управляя строковыми инструкциями (MOVS, CMPS, SCAS, LODS, STOS). Чтобы установить/сбросить этот флаг — STD и CLD.
Комментарий на полях:
Так как я в первую очередь учу асм для «разбора» кода старинных игр, тут мне для дизасма требуется в том числе знание Windows API. В отличие от языка Си, где у нас есть int, short, long, singed/unsigned и проч. — Винда использует свои собственные типы, например, WORD — беззнаковое 16-битное значение, DWORD — 32-битное (линуксоиды негодуэ). В названии переменных обязательна «венгерская нотация»: имя переменной DWORD всегда будет начинаться с dw. Взаимодействие с ОС идет через «дескрипторы» — ссылки на участок памяти или объект (файл, процесс, окно, меню и проч); например, когда вы создаете окошко, вам выдается дескриптор HWND, на который вы будете в дальнейшем ссылатся, чтобы взаимодействовать с этим окошком. Дескрипторы отличаются от указателей тем, что не всегда дают адрес объекта и не используются в арифметике.
Про реестры понятно. Теперь поговорим о памяти, то бишь о стеке. Память компьютера (RAM) делится на 4 основных сегмента (в произвольном порядке):
- Статические данные — инициализируются при запуске программы и не изменяются в процессе выполнения. Также называются глобальными, т.к. доступны из любой части кода.
- Программный код. Инструкции, который выполняет процессор.
- Куча (heap) — динамическая память, где во время работы программы постоянно создаются и удаляются объекты (именно из кучи в Си мы выделяем память при помощи команды malloc() и освобождаем при помощи free().
- Стек временное хранилище для значений регистров процедур, локальных переменных и аргументов.
Проще говоря, Стек — область памяти программы для временного хранения каких-нибудь данных, чтобы их можно было быстро использовать и управлять потоком выполнения программы.
При вызове подпрограммы или возникновении прерывания, в стек заносится
адрес возврата — адрес в памяти следующей инструкции приостановленной программы и управление передается подпрограмме или подпрограмме-обработчику. Соответственно, стек отслеживает место, куда каждая из вызванных процедур должна вернуть управление после своего завершения.
Вики
Со стеком работает регистр ESP (и порой EBP). Есть три операции работы со стеком:
push — добавление элемента (процессор декрементирует значение в регистре ESP и записывает помещаемое значение на вершину стека).
pop — удаление элемента (процессор сначала копирует удаляемое значение с вершины стека, а затем уже инкрементирует значение в регистре ESP)
peek — чтение головного элемента.
Про них будет еще рассказано ниже.
Stack Pointer (SP) — указатель стека; регистр процессора, который указывает на адрес головы стека.
Важно! Не путайте Stack pointer
с Instruction pointer (см. выше).
Всего есть 3 типа указателей:
Instruction pointer, Stack pointer, Base Pointer.
Они разные 🙂
Предположим для примера, что голова стека расположена по меньшему адресу, следующие элементы располагаются по нарастающим адресам. При каждом вталкивании слова в стек SP сначала увеличивается на 1 и затем по адресу из SP производится запись в память. При каждом извлечении слова из стека (выталкивании) сначала производится чтение по текущему адресу из SP и последующее уменьшение содержимого SP на 1. Короче… Есть правило работы со стеком: процедура, которая вошла последней, должна первой из него выйти.
Еще раз вспоминаем базовый алгоритм: процессор читает команду (aka опкод aka инструкцию) из памяти себе в регистр и начинает ее выполнение.
Пройдемся по популярным инструкциям:
Инструкции работы со стеком
MOV — поместить значение в регистр. Пример команды:
MOV EAX, 15, где
MOV — опкод; EAX — регистр; 15 — значение, которое кладется в регистр.
PUSH поместить какие-либо данные на вершину стека. один “аргумент” — источник.
PUSH 21 значение в регистре SP уменьшится на машинное слово; по адресу будет записано 21
POP — берёт верхний элемент с вершина стека стека; при этом элемент из стека удаляется и возвращается нам. “аргументом” не может быть число. После POP надо написать в регистр/переменную (туда будет помещено значение из стека).
POP EAX забираем данные с вершины стека и кладем в регистр EAX
Инструкции перехода
JMP (jump) — прыгает из одного участка кода в другой по указанному адресу.
CALL — записывает в стек адрес возврата, а потом уже делает переход по указанному адресу (соотв. адрес возврата — адрес инструкции в стеке, следующей за командой CALL).
RET (return) — выполняет выход из программы или процедуры по адресу возврата, записанному ранее инструкцией CALL.
Математические инструкции
ADD сложение
ADD EAX, 15 (результат сложения кладется в EAX)
SUB вычитание. SUB по сути является инвертированной командой ADD (с отрицательным источником).
SUB EDX, ECX (результат кладется в EDX)
NEG меняет знак числа на противоположный и меняет флаги CF, ZF, SF, OF, AF, PF.
Умножение и деление в асме довольно долго разъяснять; поэтому просто приведу список, а вы уже сами погуглите мануалы:
MUL умножение беззнаковых чисел.
IMUL умножение чисел со знаком
DIV деление чисел без знака
IDIV деление чисел со знаком
Логические инструкции
AND побитовое логическое умножение
OR побитовое логическое сложение
XOR побитовое сложение по модулю два
CMP сравнение двух чисел
TEST сравнение через логическое умножение
NOT инвертирует каждый бит
Кстати, есть прикольный лайфхак, который зовется XOR-обмен (XOR swap algorithm). Он используется, чтобы поменять местами значения в регистрах и работает быстрее, чем xchg:
XOR AX, BX
XOR BX, AX
XOR AX, BX
Пример:
a = 0101; b = 1010.
a = a ^ b // 1111
b = a ^ b // 1111 ^ 1010 = 0101
a = a ^ b // 1111 ^ 0101 = 1010
Также XOR позволяет обнулить регистры, например, XOR EAX, EAX. По сути это аналог команды MOV EAX, 0 , но работает быстрее.
Типы данных в ассемблере
Типов данных как таковых нет. По сути есть только данные, записанные в двоичной системе. Т.е. там нет десятичных чисел, символов или строк. Но есть 5 директив определения данных:
Byte (DB — define byte) — определяет переменную размером в 8 бит (1 байт). Byte всегда занимает 8 бит; если там хранится число меньшего размера, остальные биты заменяются нулями. Максимальное значение: 255.
Word (DW — define word) — слово. Состоит из 16 бит (2 байта). Максимальное значение: 65 535
Double Word (DD — define double word) — двойное слово; 4 байта; 32 бита.
Quad Word (DQ — define quad word) — учетверённое слово; 8 байт; 64 бита.
Ten Byte (DT — define ten bytes) — 10 байт.
Синтаксис:
<имя> <тип> <операнд>, ... <операнд>, например
foo DB 1010011
Определить переменную foo размером 1 байт со значением 1010011, заданным в двоичной системе счисления.
Тоже самое в шестнадцатеричной системе: foo DB 53h
Десятичной: foo DB 83d
Тоже самое в виде строки (83 в ASCII соответствует символы S):
foo db 'S' ; заметим, что можно указывать тип как в верхнем (DB), так и нижнем (db) регистре.
Для строк используется тип данных Byte (DB). По сути, строки — это просто набор последовательных байтов, то бишь массив, например:
foo db 115d, 107d, 111d, 98d, 107d, 105d
это тоже самое, что и:
foo db 'skobki'
? дает задать неинициализированную переменную
foo dd ? — определить переменную в 4 байта
DUP дает заполнить элементы последовательности одинаковыми значениями
foo dd 9 dup (5) — определить массив из 10 двойных слов и инициализировать все элементы значением 5. Таким образом:
foo dd 9 dup (5) == foo dd 5,5,5,5,5,5,5,5,5
Можем сделать такой фокус:
foo dd 9 dup (?) — определить массив с 9 неинициализированными двойными словами.
