
Продолжаем курс cs50, неделя третья, алгоритмы сортировки. Настало время лабораторки. Она очень простая:
- скачать тестовый сетап: https://cdn.cs50.net/2021/fall/labs/3/sort.zip
- внутри архива лежат три уже скомпилированные программы на C: sort1, sort2 и sort3 — это бинарники, т.е. файлы с двоичным кодом, поэтому мы не можем просмотреть их исходный код на C.
- каждая из этих программ работает по одному из алгоритмов сортировки: сортировка выбором (selection sort), пузырьковая сортировка (bubble sort) или сортировка слиянием (merge sort). В каком файле какая — мы не знаем. Наша задача — определить, какой алгоритм сортировки используется в каждом бинарнике.
В этой задаче нужно понять, какая программа использует какой алгоритм, и сделать это нужно не смотря на сам код программы, так как его не видно, а только по времени выполнения сортировки разных массивов данных. Для этого нам дают несколько файлов .txt, в которых приведены числа — есть три типа файлов:
- уже отсортированные правильно;
- рандомные (случайный порядок);
- отсортированные в обратном порядке.
В файлах есть от 5 до 50 тысяч значений, и мы можем запускать каждую из трех программ для каждого из этих 9 файлов с числами, запуск программы сортировки идет через командную строку: ./[имя_программы] [текстовый_файл.txt]
Например, запуск может выглядеть так:
./sort1 reversed50000.txt.
Чтобы узнать, сколько времени потребуется программе для сортировки, запускаем таймер через терминал:
time ./[имя_программы] [текстовый_файл.txt].
Записываем себе значение real time, и используем эти данные для анализа алгоритмов. Чтобы сдать лабораторную работу, нужно заполнить текстовый файл answer.txt — написать какая программа использует какой алгоритм и объяснить, на основании чего вы сделали такой вывод. Здесь не нужно писать сам код алгоритмов или вообще что-либо программировать. Задача сводится к анализу и логическому поиску ответа.
Штукенция
Чтобы выполнить эту лабораторную работу, я нарисовала табличку и заполнила ее данными:
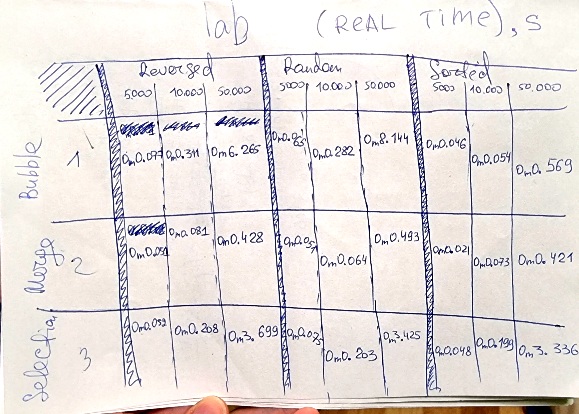
Так как никаких данных, кроме времени выполнения сортировки у нас нет, то нужно смотреть на время и аналитически догадаться, где какой алгоритм. Учитывая, что у разных алгоритмов разное минимальное и максимальное время, я первоначально сосредоточилась на сравнении данных из первой колонки (reversed) и последней колонки (sorted): это наш худший и лучший случаи. Худший, так как все данные отсортированы наоборот. И лучший, так как все числа и так в нужном порядке.
Сначала я нашла те два алгоритма, где худшие и лучшие случаи мало отличаются, так как время их выполнения близко (selection и merge), затем из я нашла алгоритм, который при росте количества обратно отсортированного массива становится заметно медленнее (bubble). Далее, как отличить selection от merge? Merge при увеличении количества данных сортирует быстрее, чем select. В конце концов я сравнила, как в целом ведет себя алгоритм, даже если числа рандомные. В итоге сначала я обнаружила bubble, а затем из двух оставшихся выделила merge.
sort1 uses: bubble sort How do you know?: reversed and sorted speed soring is different (as n^2 and n) and for the biggest random list it is the slowest sort2 uses: merge sort How do you know?: it has the same or close sorting speed for best and worst cases and it much faster than 3rd (as nlogn) sort3 uses: selection sort How do you know?: it has the same or close sorting speed for reversed and sorted lists, but it become slower with growing of numbers (as n^2)
Игроглаз
Ну а я воспользовался не менее архаичным способом — блокнотом 🙂 Получились следующие результаты:
sort 1 - slowest on random and reversed, but good at sorted bubble sort random 5000 .092 random 10000 .254 random 50000 8.145 reversed 5000 .089 reversed 10000 .285 reversed 50000 6.362 sorted 5000 .027 sorted 10000 .087 sorted 50000 .552 -- sort 2 - faster than any other for all types of data merge sort random 5000 .041 random 10000 .266 random 50000 .486 reversed 5000 .038 reversed 10000 .083 reversed 50000 .562 sorted 5000 .044 sorted 10000 .069 sorted 50000 .506 -- sort 3 - equal on any type of data selection sort random 5000 .070 random 10000 .179 random 50000 3.790 reversed 5000 .076 reversed 10000 .206 reversed 50000 3.744 sorted 5000 .047 sorted 10000 .172 sorted 50000 3.465
До встречи на новых лабах!
