В конце пятой недели курса CS50 Harvard мы изучили хэш-таблицы, с помощью которых можно решить задачу хэширования слов из текста, чтобы проверить правильность их написания по словарю (speller.c). Дается словарь, в котором на каждой новой строке перечислены слова. В отдельном файле дается текст, который программа должна проверить — какие слова в тексте написаны не правильно. Считается, что все слова, которых нет в словаре, — это неправильные слова.
Нужно не только создать код программы, который сверяет слова из текста со словарем, но и минимизировать скорость выполнения этой программы. Чтобы программа работала быстро, нужно придумать свою хэш-функцию и подобрать оптимальное количество «ведерок» в хэш-таблице (изначально предлагается 26 «ведерок»). Задание находится в файле словаря (dictionary.c) и состоит из четырех функций: загрузка словаря (load), хэш-функция (hash), проверка слов (check) и освобождение памяти (unload).
Хэш-функция
Чтобы лучше понять, что такое хэш-функцию и зачем она нужна, рассмотрим пример: предположим, что у вас есть объект, и вы хотите присвоить ему некий ключ, чтобы упростить поиск. Для решения такой задачи можно использовать простой массив и хранить там пары данных (объект и его ключ). Если же ключи длинные и их нельзя использовать напрямую в качестве индекса, следует использовать хеширование.
При хешировании длинныее ключи преобразуются в короткие с помощью хеш-функций. Затем их значения сохраняются в структуре данных, называемой хеш-таблицей . Почему хэширование позволяет сделать поиск быстрым? Дело в том, что при хешировании все записи пар (объект / ключ) распределяются равномерно по массиву и доступ к ним идет через рассчитываемое хэш-код (целое число). Чтобы рассчитать хэш-код для объекта используется алгоритм (хеш-функция), по ней вычисляет индекс, который показывает, где можно найти или вставить запись.
Как сделать хорошую хэш-функцию?
Эту функцию нужно сделать самостоятельно так, чтобы программа работала как можно быстрее. Есть разные подходы к тому, как писать быстрые хэш-функции, здесь нужно провести свое исследование и выбрать подходящий вариант. Можно ориентироваться на буквы в слове или на математические операции с буквами и другими имеющимися параметрами. Тестируя готовый вариант, можно подобрать оптимальную хэш-функцию и количество «ведерок» (ячеек).
Есть подход, в котором создается хэш-функция, дающая всегда уникальный результат. В нашей задаче нет такой необходимости, так как мы делаем «цепочки». Тем более, что даже в хорошей хэш-функции могут быть коллизии (пересечения). Поэтому можно создать хэш-функцию, которая будет быстро работать и минимизировать коллизии. Самый простой способ: сложить все буквы и умножить на какое-нибудь число (например, strlen) или прибавить фиксированное значение (например, длину слова), а потом взять от него модуль от количества ячеек.
Функция загрузки словаря
Оперирует функцией открытия файла FILE *x = fopen(dictionary, "r"), через которую мы открываем файл словаря. Далее построчно читаем каждое слово из файла, используя функцию fscanf(x, "%s", word). Для каждого слова динамически выделяем память через malloc(sizeof(node)), применяем хэш-функцию и копируем слово в созданный узел. Затем вставляем узел в нужное место хэш-таблицы. В этой же функции можно сделать подсчет количества загруженных слов из словаря.
Функция проверки
Основа этого блока — функция strcasecmp(), которая сравнивает аргументы без чувствительности к регистру. Нужно возвратить true, если слова одинаковые (то есть слово из текста есть в словаре, следовательно, оно правильное)! В этом моменте я запуталась и долго не могла понять, почему функция не правильно сравнивает слова Оказалось, что я возвращала false там, где нужно было вернуть true.
Функция освобождения памяти
Чтобы освободить память для каждого узла, нужно создать временную переменную, которая указывает на начало связанного списка (cursor) и еще одну переменную (tmp), которая изначально никуда не указывает. Затем даем tmp значение cursor, а сам cursor передвигаем на один шаг вперед. И освобождаем память tmp. Продолжая таким образом освобождать память, мы не потеряем ни одной связи.
Код программы (Игроглаз)
// Implements a dictionary's functionality
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <stdbool.h>
#include <string.h>
#include <strings.h>
#include "dictionary.h"
// Represents a node in a hash table
typedef struct node
{
char word[LENGTH + 1];
struct node *next;
}
node;
// Choose number of buckets in hash table
const unsigned int N = 4001; // 26 (alphabet) * 45 (length) = 1170
// Hash table
node *table[N];
// global variable for size_count()
unsigned int counter = 0;
// global flag for check_hash recursion search
bool flag;
// go through dictionary branch with hash-index and check is it exist there
bool check_hash(node *tabb, const char *word)
{
if (tabb == NULL) // base case
return false;
check_hash(tabb->next, word); // recursion
// compare strings and if word found - flag it up
if (strcasecmp(tabb->word, word) == 0)
flag = true;
return flag;
}
// Returns true if word is in dictionary, else false
bool check(const char *word)
{
// hash word and get the
unsigned int x = hash(word);
// reset flag for check_hash
flag = false;
if (table[x] == NULL) // paranoia: such hash doesn't exist in the dictionary
return false;
else // hash exist, so lets find is the word exist in the hash's branch
return check_hash(table[x], word);
}
// Hashes word to a number
unsigned int hash(const char *word)
{
unsigned int hash = 0;
for (int h = 0; h < LENGTH; h++) // compare with number of letters to take
{
if (word[h] == '\0')
break;
if (isalpha(word[h]))
hash += toupper(word[h]) - 'A';
}
hash *= strlen(word);
hash %= N;
// paranoia
if (hash < 0)
hash = 0;
else if (hash > N)
hash = N;
return hash;
}
// Loads dictionary into memory, returning true if successful, else false
bool load(const char *dictionary)
{
char word[LENGTH+1];
unsigned int i = 0; // will contain hash number
FILE *file = fopen(dictionary, "rb");
if (file == NULL)
return false;
while (fscanf(file, "%s", word) != EOF) // return EOF if it reach end of file.. while?
//filepointer from fopen format character array where we put the word
{
node *n = (node *)malloc(sizeof(node));
if (n == NULL)
return false;
strcpy(n->word, word); // copy from buffer to node
n->next = NULL; // point to NULL
i = hash(word); // hash word
// hash is array of linked list... table[26]
// 1) add new node to a linked list..
// start new branch of linked list
if (table[i] == NULL)
{
table[i] = n;
counter++;
}
// join to existing branch
else
{
// 1st connection to existing node
if (table[i]->next == NULL)
{
table[i]->next = n;
counter++;
}
// node already got children
else
{
n->next = table[i]->next;
table[i]->next = n;
counter++;
}
}
}
fclose(file);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int size(void)
{
return counter;
}
// Unloads dictionary from memory, returning true if successful, else false
bool unload(void)
{
node *cursor = NULL; // points to node which we look into
node *tmp = NULL; // so we won't loose child address
for (int i = 0; i < N; i++) // 76 total, starting from 0.. so from 0 to 75
{
if (table[i] != NULL)
{
cursor = table[i]; // init
tmp = table[i];
while (cursor->next != NULL)
{
cursor = tmp->next;
free(tmp);
tmp = cursor;
}
free(cursor);
}
}
return true;
}
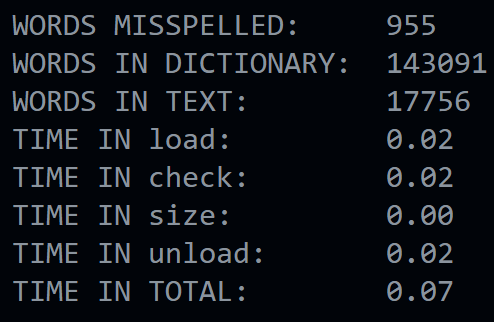
Вывод командой ./speller texts/lalaland.txt:
... < list of misspelled words >.. WORDS MISSPELLED: 955 WORDS IN DICTIONARY: 143091 WORDS IN TEXT: 17756 TIME IN load: 0.03 TIME IN check: 0.18 TIME IN size: 0.00 TIME IN unload: 0.01 TIME IN TOTAL: 0.21
Код программы (Штукенция)
// Implements a dictionary's functionality
#include <ctype.h>
#include <stdbool.h>
#include <string.h>
#include <strings.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include "dictionary.h"
int size_words = 0; // Keep track of the number of words added
// Represents a node in a hash table
typedef struct node
{
char word[LENGTH + 1];
struct node *next;
}
node;
// TODO: Choose number of buckets in hash table
const unsigned int N = 10000;
// Hash table
node *table[N];
// Returns true if word is in dictionary, else false
bool check(const char *word)
{
// TODO
// Convert word to lowercase
// Hash the word
int hash_index = hash(word);
int result;
// Create variable that points to the start of linked list
node *cursor = table[hash_index];
while (cursor != NULL)
{
result = strcasecmp(word, cursor->word); // compare without case sensitivity
if (result == 0)
{
return true;
}
cursor = cursor->next; // check next word in linked list
}
return false;
}
// Hashes word to a number
unsigned int hash(const char *word)
{
// TODO: Improve this hash function
// The output should be between 0 and N-1
unsigned int result = 0;
unsigned int word_lenth = strlen(word);
for (int i = 0; i <= word_lenth; i++)
{
result += tolower(word[i]) + word_lenth / 2;
}
return result % N;
}
// Loads dictionary into memory, returning true if successful, else false
bool load(const char *dictionary)
{
// TODO
// Open the dictionary file
FILE *dict = fopen(dictionary, "r");
if (dict == NULL)
{
printf("Could not open dictionary.\n");
return false;
}
// Read strings from file one at a time
char word[LENGTH + 1];
while (fscanf(dict, "%s", word) != EOF)
{
// Create a new node for each word
node *n = malloc(sizeof(node));
if (n == NULL)
{
printf("Not enough memory.\n");
fclose(dict);
return false;
}
// Hash word and get hash-value
int hash_index = hash(word);
strcpy(n->word, word); // Copy word
// Insert node into hash table at that location
node *head = table[hash_index]; // Create variable that points to the start of linked list
if (head != NULL)
{
n->next = table[hash_index];
}
else
{
n->next = NULL;
}
table[hash_index] = n;
size_words ++;
}
fclose(dict);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int size(void)
{
// TODO
return size_words;
}
// Unloads dictionary from memory, returning true if successful, else false
bool unload(void)
{
// TODO
for (int i = 0; i < N ; i++)
{
node *cursor = table[i]; // Create variable that points to the start of linked list
node *tmp = NULL;
while (cursor != NULL)
{
tmp = cursor;
cursor = cursor->next;
free(tmp);
}
}
return true;
}
Результат работы программы на примере ./speller texts/lalaland.txt:
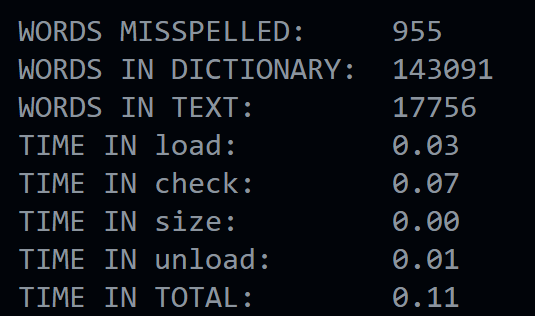
Для сравнения можно использовать решение команды CS50: