At the end of the fifth week of the CS50 Harvard course, we studied hash tables, which can be used to solve the problem of hashing words from text to check their spelling in a dictionary (speller.c). A dictionary is given in which words are listed on each new line. In a separate file, the text is given, which the program must check – which words in the text are spelled incorrectly. It is believed that all words that are not in the dictionary are wrong words.
It is necessary not only to create a program code that checks words from the text with a dictionary, but also to minimize the speed of this program. In order for the program to work quickly, you need to come up with your own hash function and choose the optimal number of buckets in the hash table (26 buckets are initially suggested). The task is located in the dictionary file (dictionary.c) and consists of four functions: dictionary loading (load), hash function (hash), word check (check) and memory release (unload).
Hash function
To better understand what a hash function is and why it is needed, let’s look at an example: suppose you have an object and you want to assign a key to it to make it easier to find. To solve such a problem, you can use a simple array and store data pairs there (an object and its key). If the keys are long and cannot be used directly as an index, hashing should be used.
In hashing, long keys are converted to short keys using hash functions. Their values are then stored in a data structure called a hash table. Why does hashing make lookups fast? The fact is that during hashing, all records of pairs (object / key) are distributed evenly over the array and access to them goes through the calculated hash code (integer). To calculate the hash code for an object, an algorithm (hash function) is used, it calculates an index that shows where the entry can be found or inserted.
How to make a good hash function?
This function needs to be done independently so that the program works as quickly as possible. There are different approaches to how to write fast hash functions, here you need to do your research and choose the appropriate option. You can focus on letters in a word or on mathematical operations with letters and other available parameters. By testing the finished version, you can choose the optimal hash function and the number of “buckets” (cells).
There is an approach in which a hash function is created that always gives a unique result. In our task, there is no such need, since we are making “chains”. Moreover, even in a good hash function there can be collisions (crossings). Therefore, it is possible to create a hash function that will be fast and minimize collisions. The easiest way is to add all the letters and multiply by some number (for example, strlen) or add a fixed value (for example, the length of a word), and then take the modulo of the number of cells from it.
Dictionary download function
Operates with the file open function FILE *x = fopen(dictionary, "r"), through which we open the dictionary file. Next, we read each word from the file line by line using the fscanf(x, "%s", word) function. For each word, dynamically allocate memory via malloc(sizeof(node)), apply the hash function, and copy the word to the created node. Then we insert the node in the right place in the hash table. In the same function, you can count the number of words loaded from the dictionary.
Check function
The basis of this block is the strcasecmp() function, which compares arguments without case sensitivity. You need to return true if the words are the same (that is, the word from the text is in the dictionary, therefore, it is correct)! At this point, I got confused and for a long time could not understand why the function does not compare words correctly. It turned out that I returned false where it was necessary to return true.
Memory release function
To free memory for each node, you need to create a temporary variable that points to the beginning of the linked list (cursor) and another variable (tmp) that initially points nowhere. Then we give tmp the value of cursor, and the cursor itself is moved one step forward. And free tmp memory. Continuing to free memory in this way, we will not lose a single connection.
Code of program by igroglaz
// Implements a dictionary's functionality
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <stdbool.h>
#include <string.h>
#include <strings.h>
#include "dictionary.h"
// Represents a node in a hash table
typedef struct node
{
char word[LENGTH + 1];
struct node *next;
}
node;
// Choose number of buckets in hash table
const unsigned int N = 4001; // 26 (alphabet) * 45 (length) = 1170
// Hash table
node *table[N];
// global variable for size_count()
unsigned int counter = 0;
// global flag for check_hash recursion search
bool flag;
// go through dictionary branch with hash-index and check is it exist there
bool check_hash(node *tabb, const char *word)
{
if (tabb == NULL) // base case
return false;
check_hash(tabb->next, word); // recursion
// compare strings and if word found - flag it up
if (strcasecmp(tabb->word, word) == 0)
flag = true;
return flag;
}
// Returns true if word is in dictionary, else false
bool check(const char *word)
{
// hash word and get the
unsigned int x = hash(word);
// reset flag for check_hash
flag = false;
if (table[x] == NULL) // paranoia: such hash doesn't exist in the dictionary
return false;
else // hash exist, so lets find is the word exist in the hash's branch
return check_hash(table[x], word);
}
// Hashes word to a number
unsigned int hash(const char *word)
{
unsigned int hash = 0;
for (int h = 0; h < LENGTH; h++) // compare with number of letters to take
{
if (word[h] == '\0')
break;
if (isalpha(word[h]))
hash += toupper(word[h]) - 'A';
}
hash *= strlen(word);
hash %= N;
// paranoia
if (hash < 0)
hash = 0;
else if (hash > N)
hash = N;
return hash;
}
// Loads dictionary into memory, returning true if successful, else false
bool load(const char *dictionary)
{
char word[LENGTH+1];
unsigned int i = 0; // will contain hash number
FILE *file = fopen(dictionary, "rb");
if (file == NULL)
return false;
while (fscanf(file, "%s", word) != EOF) // return EOF if it reach end of file.. while?
//filepointer from fopen format character array where we put the word
{
node *n = (node *)malloc(sizeof(node));
if (n == NULL)
return false;
strcpy(n->word, word); // copy from buffer to node
n->next = NULL; // point to NULL
i = hash(word); // hash word
// hash is array of linked list... table[26]
// 1) add new node to a linked list..
// start new branch of linked list
if (table[i] == NULL)
{
table[i] = n;
counter++;
}
// join to existing branch
else
{
// 1st connection to existing node
if (table[i]->next == NULL)
{
table[i]->next = n;
counter++;
}
// node already got children
else
{
n->next = table[i]->next;
table[i]->next = n;
counter++;
}
}
}
fclose(file);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int size(void)
{
return counter;
}
// Unloads dictionary from memory, returning true if successful, else false
bool unload(void)
{
node *cursor = NULL; // points to node which we look into
node *tmp = NULL; // so we won't loose child address
for (int i = 0; i < N; i++) // starting from 0..
{
if (table[i] != NULL)
{
cursor = table[i];
tmp = table[i];
while (cursor->next != NULL)
{
cursor = tmp->next;
free(tmp);
tmp = cursor;
}
free(cursor);
}
}
return true;
}
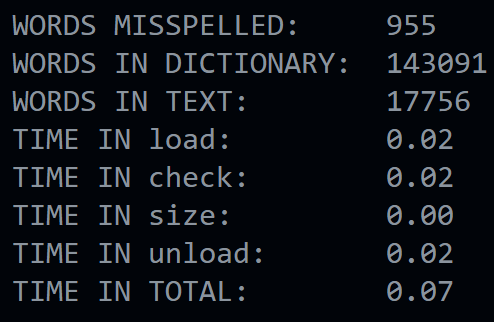
Result by command ./speller texts/lalaland.txt:
... < list of misspelled words >.. WORDS MISSPELLED: 955 WORDS IN DICTIONARY: 143091 WORDS IN TEXT: 17756 TIME IN load: 0.03 TIME IN check: 0.18 TIME IN size: 0.00 TIME IN unload: 0.01 TIME IN TOTAL: 0.21
Code of program by shtukensia
// Implements a dictionary's functionality
#include <ctype.h>
#include <stdbool.h>
#include <string.h>
#include <strings.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include "dictionary.h"
int size_words = 0; // Keep track of the number of words added
// Represents a node in a hash table
typedef struct node
{
char word[LENGTH + 1];
struct node *next;
}
node;
// TODO: Choose number of buckets in hash table
const unsigned int N = 10000;
// Hash table
node *table[N];
// Returns true if word is in dictionary, else false
bool check(const char *word)
{
// TODO
// Convert word to lowercase
// Hash the word
int hash_index = hash(word);
int result;
// Create variable that points to the start of linked list
node *cursor = table[hash_index];
while (cursor != NULL)
{
result = strcasecmp(word, cursor->word); // compare without case sensitivity
if (result == 0)
{
return true;
}
cursor = cursor->next; // check next word in linked list
}
return false;
}
// Hashes word to a number
unsigned int hash(const char *word)
{
// TODO: Improve this hash function
// The output should be between 0 and N-1
unsigned int result = 0;
unsigned int word_lenth = strlen(word);
for (int i = 0; i <= word_lenth; i++)
{
result += tolower(word[i]) + word_lenth / 2;
}
return result % N;
}
// Loads dictionary into memory, returning true if successful, else false
bool load(const char *dictionary)
{
// TODO
// Open the dictionary file
FILE *dict = fopen(dictionary, "r");
if (dict == NULL)
{
printf("Could not open dictionary.\n");
return false;
}
// Read strings from file one at a time
char word[LENGTH + 1];
while (fscanf(dict, "%s", word) != EOF)
{
// Create a new node for each word
node *n = malloc(sizeof(node));
if (n == NULL)
{
printf("Not enough memory.\n");
fclose(dict);
return false;
}
// Hash word and get hash-value
int hash_index = hash(word);
strcpy(n->word, word); // Copy word
// Insert node into hash table at that location
node *head = table[hash_index]; // Create variable that points to the start of linked list
if (head != NULL)
{
n->next = table[hash_index];
}
else
{
n->next = NULL;
}
table[hash_index] = n;
size_words ++;
}
fclose(dict);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int size(void)
{
// TODO
return size_words;
}
// Unloads dictionary from memory, returning true if successful, else false
bool unload(void)
{
// TODO
for (int i = 0; i < N ; i++)
{
node *cursor = table[i]; // Create variable that points to the start of linked list
node *tmp = NULL;
while (cursor != NULL)
{
tmp = cursor;
cursor = cursor->next;
free(tmp);
}
}
return true;
}
The result of the program on the example ./speller texts/lalaland.txt:
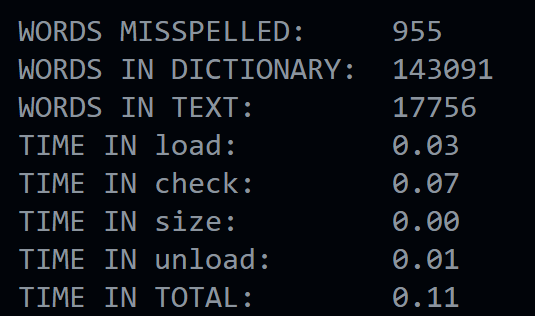
For comparison, you can use the solution of the CS50 team: